

Releasing Work In Progress
During my time at QURI, I wrote a lot of drafts and internal docs. As part of winding down my involvement, it made sense to get them public rather than let them sit in private folders. You can find the QURI drafts here. Related, I've spent recent time

QURI is moving into maintenance mode
After about seven years, QURI is moving into maintenance mode. This means we’ll ensure that key software (Guesstimate and SquiggleHub) is maintained, but we won’t be developing new software or doing new research. Background I started QURI in 2019. At that point I was excited about projects at

Upcoming Workshops: Automated Research Wikis with Claude Code
I’ve been using Claude Code to automate wiki and book production. Lately, it’s become surprisingly straightforward to generate useful, many-page research documents, especially when paired with online document libraries. If you’re in the Bay Area, I’m running two workshops soon: * MoxSF (next Thursday, San Francisco)
Opinion Fuzzing: A Proposal for Reducing & Exploring Variance in LLM Judgments Via Sampling
Summary LLM outputs vary substantially across models, prompts, and simulated perspectives. I propose "opinion fuzzing" for systematically sampling across these dimensions to quantify and understand this variance. The concept is simple, but making it practically usable will require thoughtful tooling. In this piece I discuss what opinion fuzzing
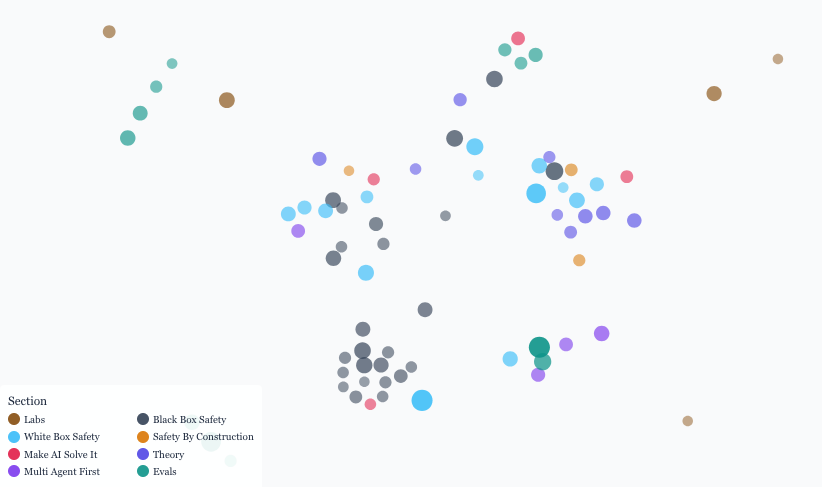
New Collaboration: Shallow Review of Technical AI Safety, 2025
We recently collaborated with the Arb Research team on their latest technical AI safety review. This document provides a strong overview of the space, and we built a website to make it significantly more manageable. The interactive website: shallowreview.ai The review examines major research directions in technical AI safety

Announcing RoastMyPost
Today we're releasing RoastMyPost, a new application for blog post evaluation using LLMs. Try it Here TLDR * RoastMyPost is a new QURI application that uses LLMs and code to evaluate blog posts and research documents. * It uses a variety of LLM evaluators. Most are narrow checks: Fact Check,
Beyond Spell Check: 15 Automatable Writing Quality Checks
I've been developing RoastMyPost (currently in beta) and wrestling with how to systematically analyze documents. The space of possible document checks is vast, easily thousands of potential analyses. Building on familiar concepts like "spell check" and "fact check," I've made a taxonomy
Updated LLM Models for SquiggleAI
We've upgraded SquiggleAI to use Claude Sonnet 4.5, Claude Haiku 4.5, and Grok Code Fast 1. This is a significant upgrade over the previous Claude Sonnet 3.7 and Claude Haiku 3.5. All three are available now. Initial testing shows meaningful improvements in code generation
Shape Squiggle's Future: Take our Squiggle Survey
Dear Squiggle Community, At QURI, we're focused on tools that advance forecasting and epistemics to improve decision-making. As you know, we care deeply about evaluation, and we're holding a survey on Squiggle to better understand how and why people use our work. Honestly, developing this
A Sketch of AI-Driven Epistemic Lock-In
Epistemic status: speculative fiction It's difficult to imagine how human epistemics and AI will play out. On one hand, AI could provide much better information and general intellect. On the other hand, AI could help people with incorrect beliefs preserve those false beliefs indefinitely. Will advanced AIs attempting
Evaluation Consent Policies
Epistemic Status: Early idea A common challenge in nonprofit/project evaluation is the tension between social norms and honest assessment. We've seen reluctance for effective altruists to publicly rate certain projects because of the fear of upsetting someone. One potential tool to use could be something like an
Recent Updates
Squiggle AI & Sonnet 3.7 We've updated Squiggle AI to use the new Anthropic Sonnet 3.7 model. In our limited experimentation with it so far, it seems like this model is capable of making significantly longer Squiggle models (roughly ~200 lines to ~500 lines), but that