

Announcing RoastMyPost
Today we're releasing RoastMyPost, a new application for blog post evaluation using LLMs.
TLDR
- RoastMyPost is a new QURI application that uses LLMs and code to evaluate blog posts and research documents.
- It uses a variety of LLM evaluators. Most are narrow checks: Fact Check, Spell Check, Fallacy Check, Math Check, Link Check, Forecast Check, and others.
- Optimized for EA & Rationalist content with direct import from EA Forum and LessWrong URLs. Other links use standard web fetching.
- Works best for 200 - ~10,000 word documents with simple formatting. It can also do basic reviewing of Squiggle models. Longer documents and documents in LaTeX will experience slowdowns and errors.
- Open source, free for reasonable use[1]. Public examples are here.
- Experimentation encouraged! We're all figuring out how to best use these tools.
How It Works
- Import a document. Submit markdown text or provide the URL of a publicly accessible post.
- Select evaluators to run. A few are system-recommended. Others are custom evaluators submitted by users. Quality varies, so use with appropriate skepticism.
- Wait 1-5 minutes for processing. (potentially more if the site is busy)
- Review the results.
- Add or re-run evaluations as needed.
Screenshots
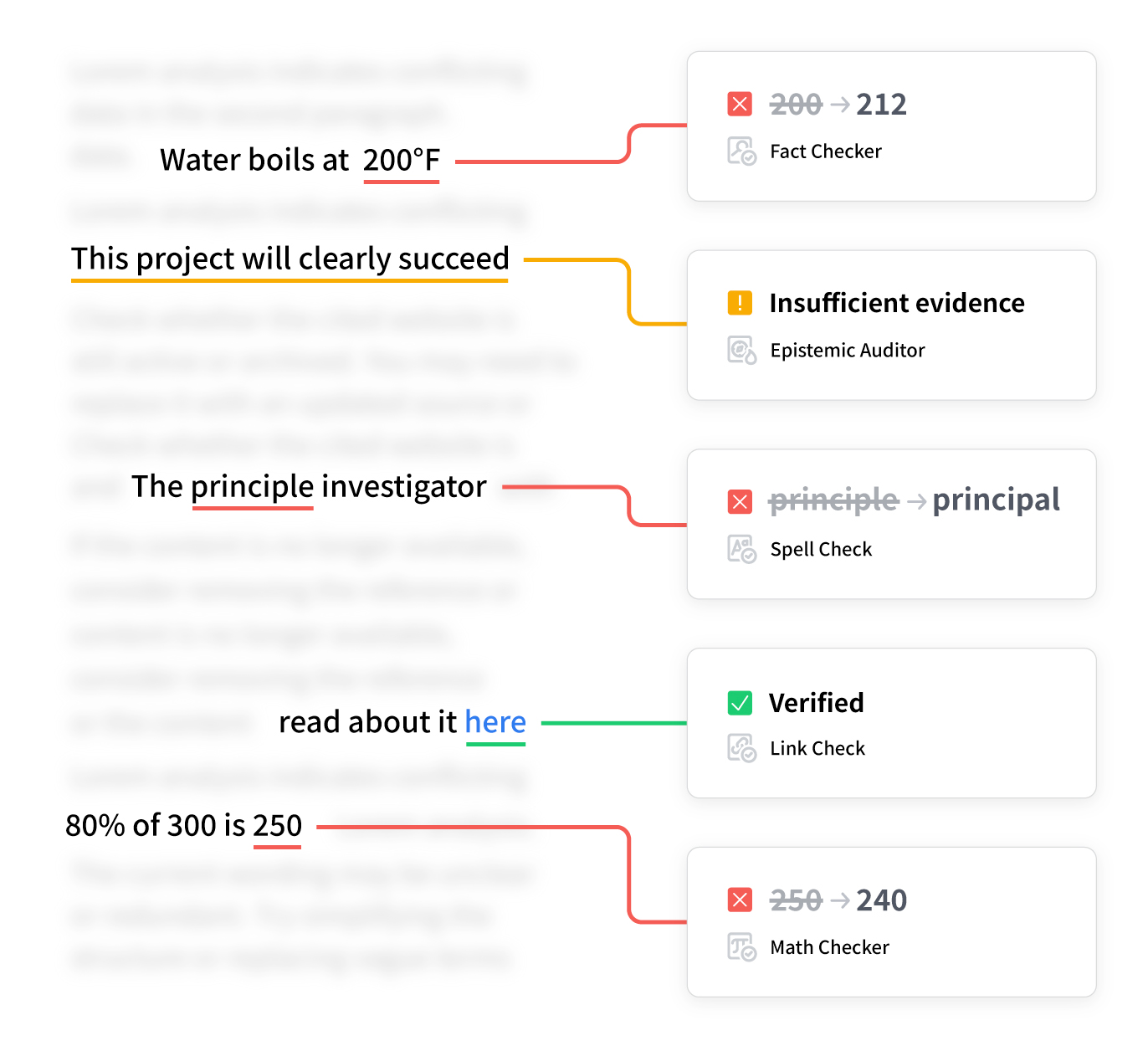
Reader Page
The reader page is the main article view. You can toggle different evaluators, each has a different set of inline comments.
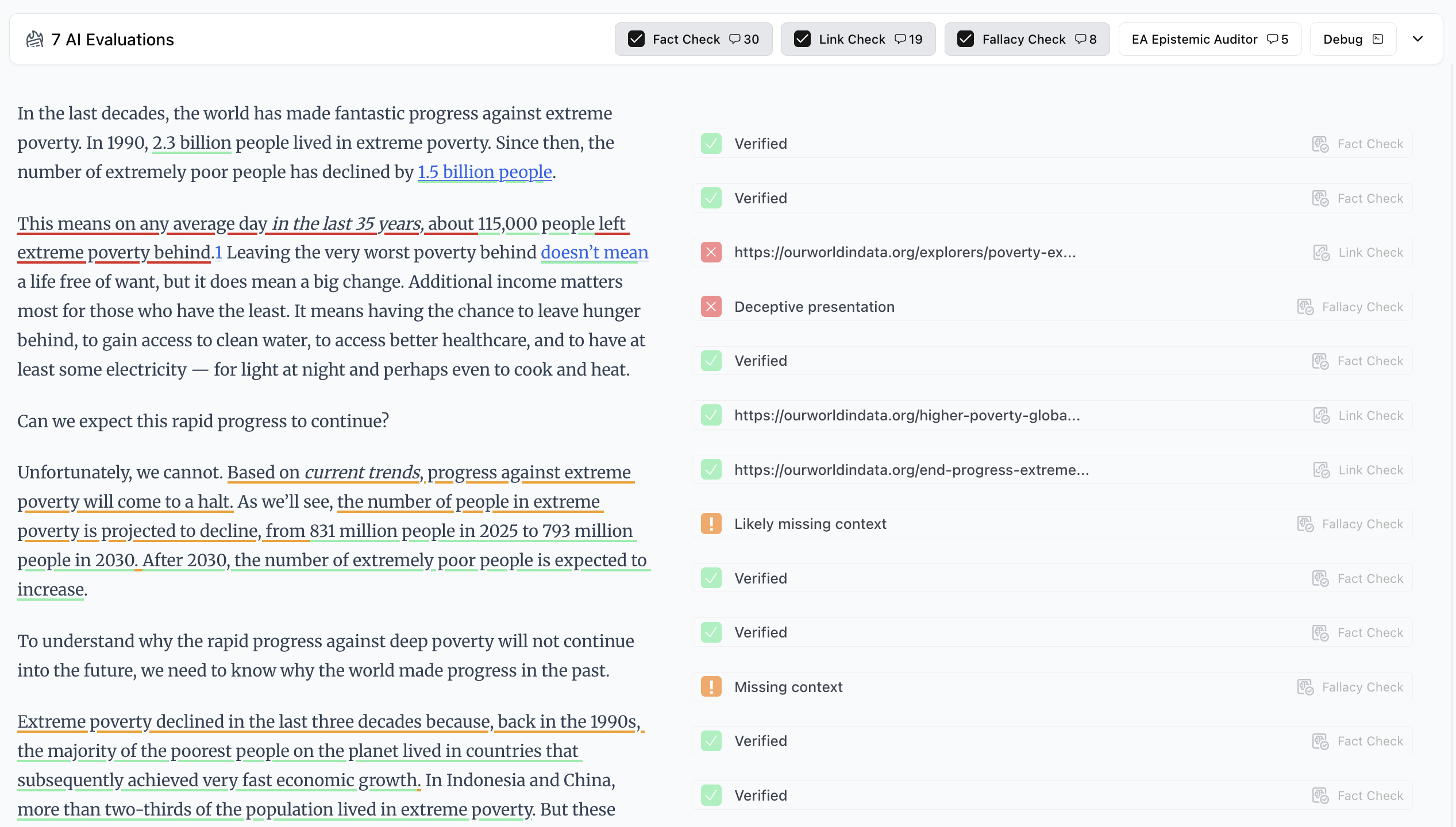
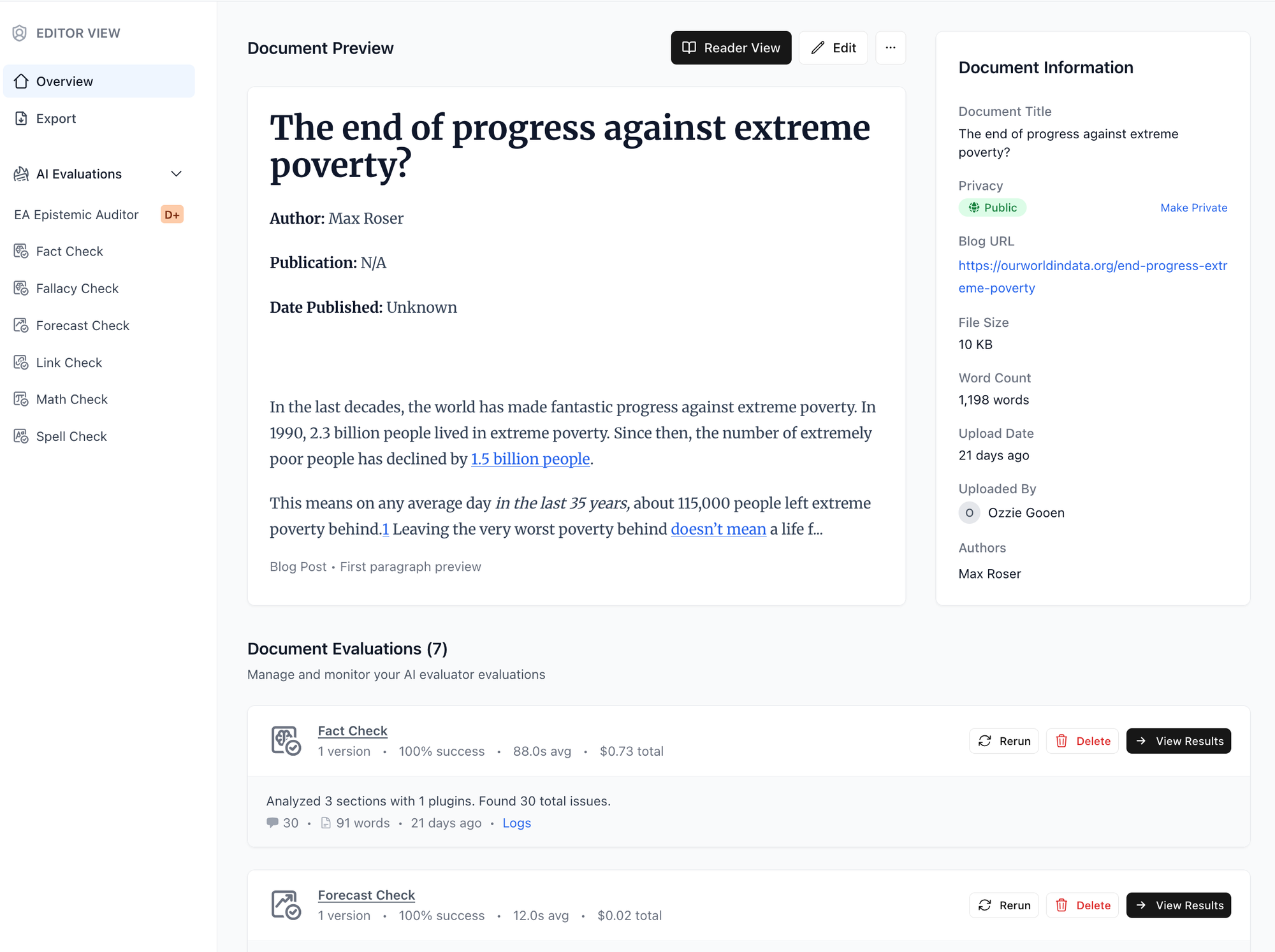
Editor Page
Add/remove/rerun evaluations and make other edits.
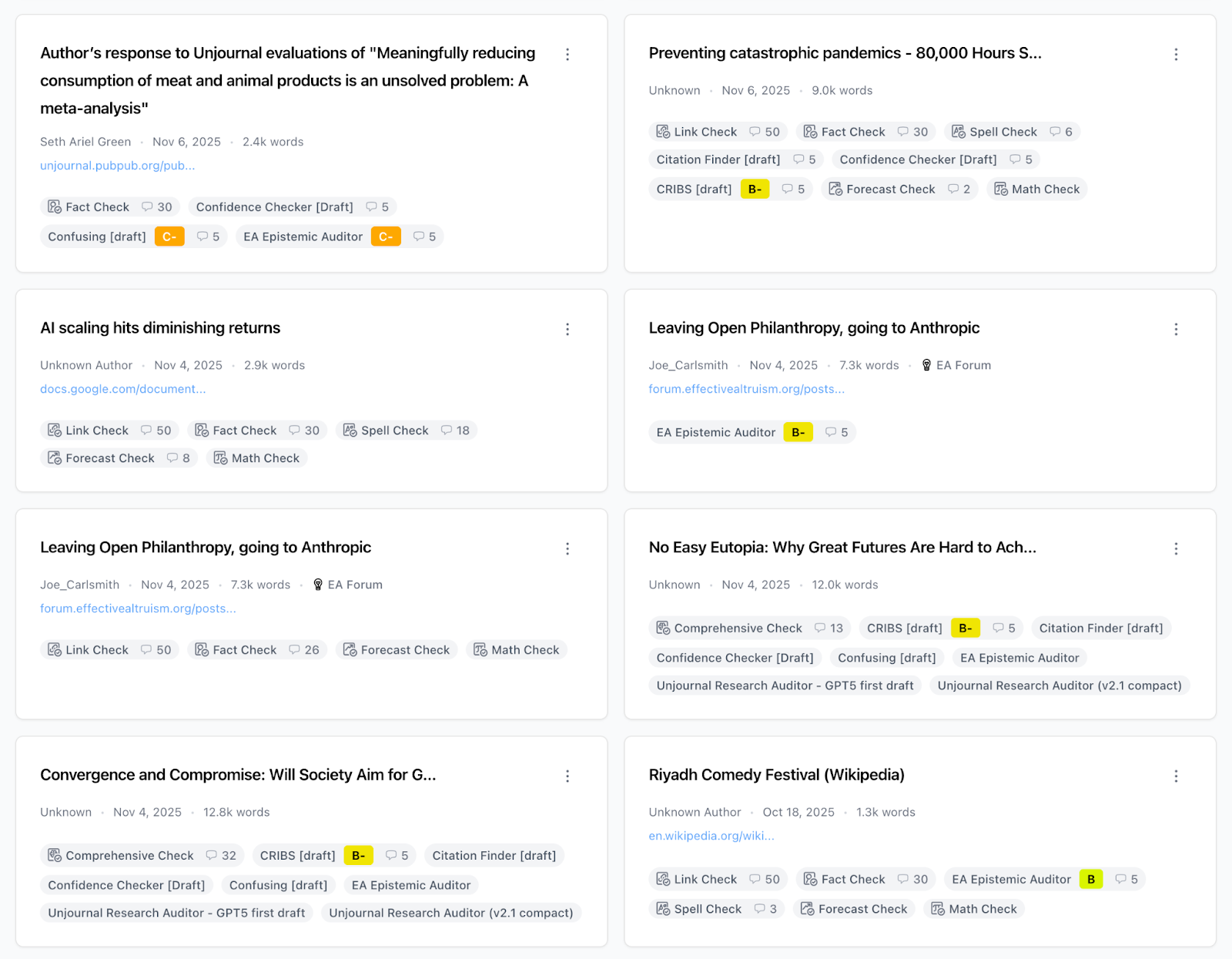
Posts Page
Current AI Agents / Workflows
| Agent Name | Description | Technical Details | Limitations |
|---|---|---|---|
| Fact Check | Verifies the accuracy of facts. | Looks up information with Perplexity, then forms a judgement. | Often makes mistakes due to limited context. Often limited to narrow factual disputes. Can quickly get expensive, so we only run a limited number of times per post. |
| Spell Check | Finds spelling and grammar mistakes. | Runs a simple script to decide on UK vs. US spelling, then uses an LLM for spelling/grammar mistakes. | Occasionally flags other sorts of issues, like math mistakes. Often incorrectly flags issues of UK vs. US spellings. |
| Fallacy Check | Flags potential logical fallacies and similar epistemic issues. | Uses a simple list of potential error types, with Sonnet 4.5. Does a final filter and analysis. | Overly critical. Sometimes misses key context. Doesn't do internet searching. Pricey. |
| Forecast Check | Finds binary forecasts mentioned in posts. Flags cases where the result is very different to what the author stated. | Converts them to explicit forecasting questions, then sends this to an LLM forecasting tool. This tool uses Perplexity searches and multiple LLM queries. | Limited to binary percentage forecasts, which are fairly infrequent in blog posts. Has limited context, so sometimes makes mistakes given that. Uses a very simple prompt for forecasting. |
| Math Check | Verifies straightforward math equations. | Attempts to verify math results using Math.js. Falls back to LLM judgement. | Mainly limited to simple arithmetic expressions. Doesn't always trigger where would be best. Few posts have math equations. |
| Link Check | Detects all links in a document. Checks that a corresponding website exists. | Uses HEAD requests for most websites. Uses the API for EA Forum and LessWrong posts, but not other content like Tag or user pages yet. | Many websites block automated requests like this. Also, this doesn't check that the content is relevant, just that a website exists. |
| EA Epistemic Auditor | Provides some high-level analysis and a numeric review. | A simple prompt that takes in the entirety of a blog post. | Doesn't do internet searching. Limited to 5 comments per post. It's fairly rough and could use improvement. |
Is it Good?
RoastMyPost is useful for knowledgeable LLM users who understand current model limitations. Modern LLMs are decent but finicky at feedback and fact-checking. The false positive rate for error detection is significant. This makes it well-suited for flagging issues for human review, but not reliable enough to treat results as publicly authoritative.
Different checks suit different content types. Spell Check and Link Check work across all posts. Fact Check and Fallacy Check perform best on fact-dense, rigorous articles. Use them selectively.
Results will vary substantially between users. Some will find workflows that extract immediate value; others will find the limitations frustrating. Performance will improve as better models become available. We're optimistic about LLM-assisted epistemics long-term. Reaching the full vision requires substantial development time.
Consider this an experimental tool that's ready for competent users to test and build on.
What are Automated Writing Evaluations Good For?
Much of our focus with RoastMyPost is exploring the potential of automated writing evaluations. Here's a list of potential use cases for this technology.
RoastMyPost now is not reliable and mature enough for all of this. Currently it handles draft polishing and basic error detection decently, but use cases requiring high-confidence results (like publication gatekeeping or public trust signaling) remain aspirational.
1. Individual authors
- Draft polishing: Alice is writing a blog post and wants it to be sharper and more reliable. She runs it through RoastMyPost to catch spelling mistakes, factual issues, math errors, and other weaknesses.
- Public trust signaling: George wants readers to (correctly) see his writing as reputable. He runs his drafts through RoastMyPost, which verifies the key claims. He then links to the evaluation in his blog post, similar to Markdown Badges on GitHub or GitLab. (Later, this could become an actual badge.)
2. Research teams
- Publication gatekeeping: Sophie runs a small research organization and wants LLMs in their quality assurance pipeline. Her team uses RoastMyPost to help evaluate posts before publishing.
- LLM-assisted workflows: Samantha uses LLMs to draft fact-heavy reports, which often contain hallucinated links and mathematical errors. She builds a workflow that runs RoastMyPost on the LLM outputs and uses the evaluations to drive automated revisions.
3. Readers
- Pre-flight checks for reading: Maren is a frequent blog reader. Before investing time in a post, they check its public RoastMyPost evaluations to see whether it contains major errors.
- Deeper comprehension and critique: Chase uses RoastMyPost to better understand the content they read. They can see extra details, highlighted assumptions, and called-out logical fallacies, which helps them interpret arguments more critically.
4. Researchers studying LLMs and epistemics
- Model comparison: Julian is a researcher evaluating language models. He runs RoastMyPost on reports produced by several models and compares the resulting evaluations.
- Meta-epistemic insight: Mike is interested in how promising LLMs are for improving researcher epistemics. He browses RoastMyPost evaluations and gets a clearer sense of current strengths and limitations.
Privacy & Data Confidentiality
Users can make public or private documents.
We use a few third-party providers that require access to data. Primarily Anthropic, Perplexity, and Helicone. We don't recommend using RoastMyPost in cases where you want strong guarantees of privacy.
Private information is accessible to our team, who will occasionally review LLM workflows to look for problems and improvements.
Technical Details
Most RoastMyPost evaluators use simple programmatic workflows. Posts are split into chunks, then verification and checking runs on each chunk individually.
LLM functionality and complex operations are isolated into narrow, independently testable tools with web interfaces. This breaks complex processes into discrete, (partially) verifiable steps.
Almost all LLM calls are to Claude Sonnet 4.5, with the main exception of calls to Perplexity via the OpenRouter API. We track data with Helicone.ai for basic monitoring.
Here you can see fact checking and forecast checking running on one large document. Evaluators run checks in parallel where possible, significantly reducing processing time.
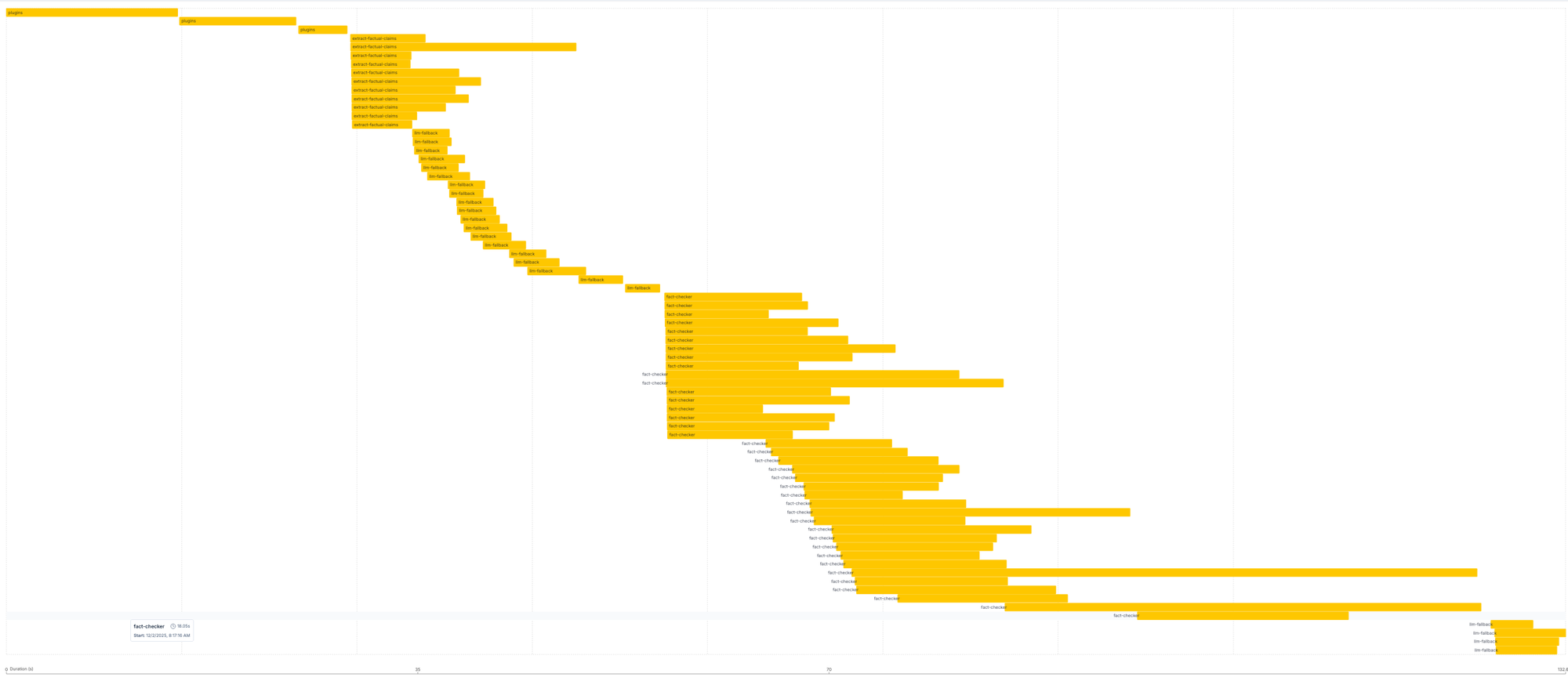
This predefined workflow approach is simple and fast, but lacks some benefits of agentic architectures. We've tested agentic approaches but found them substantially more expensive and slower for marginal gains. The math validation workflow uses a small agent; everything else is direct execution. We'll continue experimenting with agents as models improve.
Building Custom Evaluators
The majority of RoastMyPost's infrastructure is general-purpose, supporting a long tail of potential AI evaluators.
Example evaluator ideas:
- Organization style guide checker - Enforce specific writing conventions, terminology, or formatting requirements
- Domain-specific fact verification - Medical claims, economic data, technical specifications, etc.
- Citation format validator - Check references against specific journal requirements (APA, Chicago, Nature, etc.)
- Argument structure analyzer - Map claims, evidence, and logical connections
- Readability optimizer - Target specific audiences (general public, technical experts, policymakers)
The app includes basic functionality for creating custom evaluators directly in the interface. More sophisticated customization is possible through JavaScript-based external evaluators.
If you're interested in building an evaluator, reach out and we can discuss implementation details.
Try it Out
Visit roastmypost.org to evaluate your documents. The platform is free for reasonable use and is being improved.
Submit feedback, bug reports, or custom evaluator proposals via GitHub issues or email me directly.
We're particularly interested in hearing about AI evaluator quality and use cases we haven't considered.
[1] At this point, we don't charge users. Users have hourly and monthly usage limits. If RoastMyPost becomes popular, we plan on introducing payments to help us cover costs.